AUTOMATIC SPEECH RECOGNITION FOR SPEECH SUBTITLING
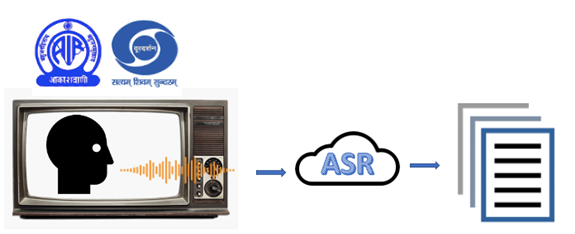
Prasar Bharati is India’s largest broadcasting agency, broadcasting audio and video content via All India Radio and Doordarshan. It has a humungous wealth of audio and video content. In this age of digitization and AI, machine learning technologies have opened up vast opportunities. A proper content analysis can help in efficient search, recommendation, accessibility, translation and so on. In this project, we propose to develop and deploy automatic speech recognition (ASR) technologies for Prasar Bharati’s multimedia content.
This project involves implementing an automatic speech recognition (ASR) system for certain languages. It will convert speech audio into a textual form. Specifically, it will be a conversational large vocabulary continuous speech recognition (LVCSR) system in its final form.
ARCHIVAL CONTENT RETRIEVAL THROUGH AUDIO AND TEXT QUERY
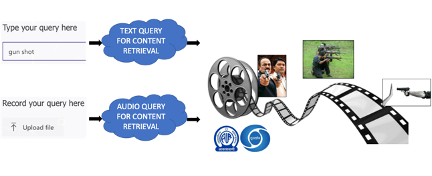
In this age of digitization and AI, machine learning technologies have opened up vast opportunities. A proper content analysis can help in efficient search, recommendation, accessibility, translation and so on. In this project, we propose to develop and deploy audio-based content retrieval technologies for Prasar Bharati’s multimedia content.
The overarching goal of this project is audio-based content retrieval. We will develop two kinds of retrieval methods, viz., extracting text labels from audio (audio tagging) and direct audio matching (audio fingerprinting).